
- 분류 전체보기 (571)

- [Snow-ball] 책 (47)
- [Snow-ball]돈 (106)
- [Snow-ball]직업군 관련 (13)
- [Snow-ball]프로그래밍(컴퓨터) (337)
- 자격증 (1)
- 운영체제(Operating System) (2)
- IT (2)
- C, C++ (24)
- 프로그래밍 및 컴퓨터 개론 이론 (42)
- java (43)
- Linux(리눅스) (11)
- github(깃허브) (5)
- 자바스크립트(JavaScript) (39)
- 타입스크립트(TypeScript) (1)
- DATABASE (6)
- Algorithm (12)
- Algorithm Training (92)
- 통합개발환경Integrated Developmen.. (2)
- 자료구조 (3)
- 네트워크 (17)
- 미니앱 (2)
- NPM (3)
- 여러가지 (16)
- 프로그래밍 실수 (11)
- cloud (3)
- [Snow-ball]server (34)
- [Snow-ball]front (30)
- 개인 사유 (1)
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 투자
- 다독
- 알고리즘트레이닝
- 서평
- 자바스크립트
- 프로그래머스 알고리즘 공부
- Java
- JavaScript
- C++
- 재테크
- 주식
- 지혜를가진흑곰
- C
- 자바
- 책을알려주는남자
- 책알남
- algorithmStudy
- 백준알고리즘
- 독후감
- 경제
- 독서
- 알고리즘 공부
- 채권
- 돈
- 알고리즘공부
- 성분
- 화장품
- algorithmtraining
- algorithmTest
- 프로그래밍언어
- Today
- Total
탁월함은 어떻게 나오는가?
[알고리즘] 퀵 정렬(Quick Sort) 알고리즘 개념과 원리에 대해 쉽고 빠르게 공부해보자 [C언어] 본문
[알고리즘] 퀵 정렬(Quick Sort) 알고리즘 개념과 원리에 대해 쉽고 빠르게 공부해보자 [C언어]
Snow-ball 2022. 2. 3. 10:36퀵 정렬(Quick Sort) 알고리즘 개념
- 퀵 정렬은 찰스 앤터니 리처드 호어가 개발한 정렬 알고리즘이다.
- 퀵 정렬은 분할 정복(divide and conquer) 방법을 통해 리스트를 정렬한다.
- 다른 원소와의 비교만으로 정렬을 수행하는 비교 정렬에 속한다.
- 퀵 정렬은 n개의 데이터를 정렬할 때, 최악의 경우에는 O(n^2)번의 비교를 수행하고, 평균적으로 O(n log n)번의 비교를 수행한다.
- 퀵 정렬의 내부 루프는 대부분의 컴퓨터 아키텍처에서 효율적으로 작동하도록 설계되어 있고(그 이유는 메모리 참조가 지역화되어 있기 때문에 CPU 캐시의 히트율이 높아지기 때문이다), 대부분의 실질적인 데이터를 정렬할 때 제곱 시간이 걸릴 확률이 거의 없도록 알고리즘을 설계하는 것이 가능하다. 또한 매 단계에서 적어도 1개의 원소가 자기 자리를 찾게 되므로 이후 정렬할 개수가 줄어든다. 그렇기에 일반적인 경우 퀵 정렬은 다른 O(n log n) 알고리즘에 비해 훨씬 빠르게 동작한다.
퀵 정렬 알고리즘 구체적인 개념 및 동작 원리
- 하나의 리스트를 피벗을 기준으로 두 개의 비균등한 크기로 분할하고 분할된 부분 리스트를 정렬한 다음, 두 개의 정렬된 부분 리스트를 합하여 전체가 정렬된 리스트가 되게 하는 방법이다.
- 퀵 정렬은 3단계로 이루어져있다.
1단계. 분할(Divide) : 입력 배열을 피벗을 기준으로 비균등하게 2개의 부분 배열(피벗을 중심으로 왼쪽 = 피벗보다 작은 요소들, 오른쪽 = 피벗보다 큰 요소들)로 분할한다.
2단계. 정복(Conquer) : 부분 배열을 정렬한다. 부분 배열의 크기가 충분히 작지 않으면 순환 호출을 이용하여 다시 분할 정복 방법을 적용한다.
3단계. 결합(Combine) : 정렬된 부분 배열들을 하나의 배열에 합병한다.
- 순환 호출이 한번 진행될 때마다 최소한 하나의 원소(피벗)는 최종적으로 위치가 정해지므로, 이 알고리즘은 반드시 끝난다는 것을 보장할 수 있다.
동작원리
1. 리스트 가운데서 하나의 원소를 고른다. 이렇게 고른 원소를 피벗(pivot - 기준점을 의미하기 떄문에 다르게 불러도 된다. 다만 피벗이라 많이 칭함)이라고 한다.
2. 피벗 앞에는 피봇보다 값이 작은 모든 원소들이 오고, 피벗 뒤에는 피벗보다 값이 큰 모든 원소들이 오도록 피벗을 기준으로 리스트를 둘로 나눈다. 이렇게 리스트를 둘로 나누는 것을 분할이라고 한다. 분할을 마친 뒤에 피벗은 더 이상 움직이지 않는다.
3. 분할된 두 개의 작은 리스트에 대해 재귀적으로 이 과정을 반복한다. 재귀는 리스트의 크기가 0이나 1이 될 때까지 반복된다.
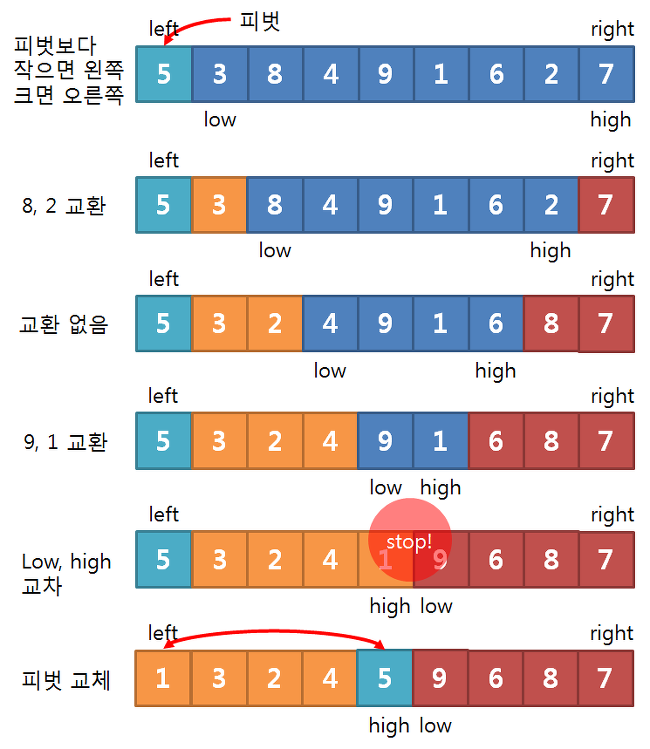
이미지로 보는 동작 절차
1) 배열의 첫 번째 값(5)를 피벗(pivot)으로 설정한다.
2) low 는 left + 1 자리부터 피벗(5)와 비교하면서 한칸씩 증가한다.
3) high 는 right 자리에서부터 피벗(5)와 비교하면서 한칸씩 감소한다.
4) 위의 절차를 반복한다. low와 high가 엇갈리면 정지한다.
5) 피벗값과 high 값을 SWAP한다.
6) 피벗을 기준으로 왼쪽, 오른쪽 두개의 배열을 1~5번을 반복한다.
7) 더 이상 나눠질 수 없을 때까지 재귀적으로 반복한다.
8) 정렬이 완료된다.
퀵 정렬 C언어 코드 :
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
#include <stdio.h>
int number = 10;
int data[] = {1, 10, 5, 8, 7, 6, 4, 3, 2, 9};
void show() {
int i;
for (i = 0; i < number; i++) printf("%d " , data[i]);
}
void quickSort(int *data, int start, int end) {
printf("start = %d\n", start);
if (start >= end) return; // 원소가 1개인 경우 그대로 리턴
int pivot = start; // 피봇은 첫 번째 원소
int i = start + 1, j = end, temp;
while(i <= j) { // 엇갈릴 때까지 반복
while(i <= end && data[i] <= data[pivot]) i++; // 피봇 값보다 큰 값을 만날 때까지
while(j > start && data[j] >= data[pivot]) j--; // 피봇 값보다 작은 값을 만날 떄까지
if(i > j) {
temp = data[j];
data[j] = data[pivot];
data[pivot] = temp;
} else {
temp = data[i];
data[i] = data[j];
data[j] = temp;
}
}
quickSort(data, start, j - 1);
quickSort(data, j + 1, end);
}
int main(void) {
quickSort(data, 0, number - 1);
show();
return 0;
}
|
cs |
퀵 정렬 알고리즘 특징
장점
- 대부분의 경우에 속도가 빠르다.
- 대부분의 경우 시간 복잡도가 O(n log n)을 가지고 있어서 다른 정렬 알고리즘과 비교했을 때 빠른편이다.
- 추가 메모리 공간을 필요로 하지 않는다 - 퀵 정렬은 O(log n)만큼의 메모리를 필요로 한다.
단점
- 정렬된 리스트(최악)에 대해서는 퀵 정렬의 불균형 분할에 의해 오히려 수행시간이 많이 걸린다.
베타존 : 네이버쇼핑 스마트스토어
나를 꾸미다 - 인테리어소품 베타존
smartstore.naver.com
'[Snow-ball]프로그래밍(컴퓨터) > Algorithm' 카테고리의 다른 글
| [algorithm 이론] 자주 접할 수 있는 알고리즘시간 복잡도 정리 (0) | 2022.03.15 |
|---|---|
| [알고리즘] 퀵 정렬(Quick Sort) 알고리즘 개념과 원리에 대해 쉽고 빠르게 공부해보자 [C언어] (0) | 2022.02.03 |
| [알고리즘] 삽입 정렬(Insertion Sort) 알고리즘 개념과 원리에 대해 쉽고 빠르게 공부해보자 [C언어] (0) | 2022.02.01 |
| [알고리즘] 버블 정렬(Bubble Sort) 알고리즘 개념과 원리에 대해 쉽고 빠르게 공부해보자 [C언어] (0) | 2022.01.31 |
| [알고리즘] 선택 정렬(Selection Sort) 알고리즘 개념과 원리에 대해 쉽고 빠르게 공부해보자 [C언어] (1) | 2022.01.30 |



